
【Unity】スイカ風マージパズルゲームの作り方 その1【2024年最新】
Unityを使ってスイカ風のマージパズルゲームを作成する方法を解説します。
今回はUI ToolkitというUnityの中でも最新のUIフレームワークを使ってUIを作成します。 まだ開発途上のため古いバージョンでは使えない機能なども多いため、今回は最新のUnity 6(旧Unity2023)を使っていきます。
目次
例えば 歩と歩をくっつけると、香車になります。
王将と王将をくっつけると、消えます。
ゲームオーバーになる条件は、容器に入れた駒が上まで溜まり、スポナーが持っている駒と接触するとゲームオーバーとなります。
駒をくっつけていくと、スコアがたまるので、ハイスコアを目指して遊びます。
必要なソフトウェア・環境
- Unity 6(Unity2023) (v: 6000.0.13f1)
プロジェクト作成
まずはUnity Hubを起動し、新規プロジェクトを作成します。

| 項目 | 値 |
|---|---|
| Editor Version | 6000.0.13f1 |
| プロジェクト名 | MergePuzzleGame |
| テンプレート | Universal 2D |
プロジェクトのテンプレートは「Universal 2D」を選択します。
プロジェクト名は「MergePuzzleGame」、プロジェクトの場所は任意の場所に作成してください。

Gameウィンドウの設定
次にGameウィンドウの設定を行います。
- Gameウィンドウ > Aspect > Full HD (1920x1080)
と設定します
シーンの編集、ゲームオブジェクトの作成
シーン名を「GameSceneに変更し、シーンを保存します。
容器の作成
容器のゲームオブジェクト作成
まずは、駒を入れる容器を作成します。
CreateEmptyを選択し、名前を「Boxとして作成します。
- Box
- Position: (0, -1, 0)
- Scale: (1, 1, 1)
Boxオブジェクトの下に下記の4つのオブジェクトを作成します。
- Field
- 2D Object > Sprite > Square
- 名前を「Field」として作成します。
- Position: (0, 0, 0)
- Scale: (6, 7, 1)
- Color: RGBA(255, 255, 255, 160)
- LeftWall
- 2D Object > Sprite > Square
- 名前を「LeftWall」として作成します。
- Position: (-3, 0, 0)
- Scale: (0.3, 7, 1)
- Color: RGBA(255, 160, 255, 255)
- RightWall
- 2D Object > Sprite > Square
- 名前を「RightWall」として作成します。
- Position: (3, 0, 0)
- Scale: (0.3, 7, 1)
- Color: RGBA(255, 160, 255, 255)
- BottomWall
- 2D Object > Sprite > Square
- 名前を「BottomWall」として作成します。
- Position: (0, -3.5, 0)
- Scale: (6.3, 0.3, 1)
- Color: RGBA(255, 160, 255, 255)
作成が完了すると画像のようになります。

容器にRigidbody2Dの追加
Box配下のWallオブジェクトにRigidbody2Dを追加します。
Hierarchyから「LeftWall」、「RightWall」、「BottomWall」を選択し、Add Component > Rigidbody2Dを選択します。

Rigidbody2Dを追加すると、物理演算の影響を受けるようになります。
これによって、この後作る上から落とす駒(ボール)を落としたときに、容器の壁で跳ね返るようになります。
ただデフォルトではRigidbody2Dを追加すると重力の影響を受けて、下に落ちてしまうので、それを防ぐために以下の設定を行います。
Rigidbody2Dの設定から Constraints > Freeze Position X, Y にそれぞれチェックを入れます。 同様に Constraints > Freeze Rotation Z にもチェックを入れます。

容器にBoxCollider2Dの追加
Box配下のWallオブジェクトにBoxCollider2Dを追加します。
Hierarchyから「LeftWall」、「RightWall」、「BottomWall」を選択し、Add Component > BoxCollider2Dを選択します。
これで容器が作成できました。
駒の作成(ボールの作成)
次に落としたり、容器に溜まっていく実際のパズルの要素である駒(ボール)を作成します。
画像のインポート
まずは画像を用意します。
今回は将棋の駒を使うので、将棋の駒の画像を用意します。
ここでは駒の画像を使いますが、ボールの画像など任意の画像を複数用意してください。
注意点としては画像のサイズはすべて同じにしてください。調整が大変になります。
種類によって大きさを変更する必要はあるのですが、これらの設定はUnity上で行います。
駒画像を管理するためにフォルダを作成します。
Assets > Create > Folderを選択し、名前を「Sprites」として作成します。
作成したSpritesフォルダに駒(ボール)の画像をドラッグ&ドロップします。
Pixels Per Unitの設定
画像のサイズによってPixels Per Unitを設定します。
Pixels Per Unitは画像のピクセル数を1ユニットとして扱う設定です。

今回の画像は93x103なので、縦のピクセル数に合わせて103に設定しました。
本来は正方形の画像を使うのが良いですが、今回は縦長の画像を使っているため、縦のピクセル数に合わせて設定しました。
もし 200x200の画像を使う場合は、200に設定することになります。
駒(ボール)のゲームオブジェクト作成
次に駒(ボール)のゲームオブジェクトを作成します。
Spritesフォルダにインポートした画像をHierarchyにドラッグ&ドロップします。
まずは一番小さい駒である「歩兵」をゲームオブジェクトを作成します

駒(ボール)のゲームオブジェクトが作成されます。
下記のように一旦初期位置に設定します。
- 駒(ボール)
- Position: (0, 0, 0)
- Scale: (1, 1, 1)
駒にRigidbody2Dの追加
駒(ボール)にRigidbody2Dを追加します。

Rigidbody2Dを追加することで、駒(ボール)が物理演算の影響を受けるようになります。
これによって、駒(ボール)が重力によって落ち、容器の壁で止まるようになります。
駒にPolygonCollider2Dの追加
駒(ボール)にPolygonCollider2Dを追加します。
PolygonCollider2Dを追加することで、駒(ボール)が物理演算の影響を受けるようになります。
今回は題材を将棋の駒にしたので、PolygonCollider2Dを使って駒の形に合わせて当たり判定を設定します。
もし、円形の画像を使う場合はCircleCollider2Dで設定することもできます。

PolygonCollider2Dの設定
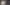
基本的に追加したPolygonCollider2Dは画像の形に合わせて自動で設定されますが、必要に応じて編集することもできます。
Sceneパネルを開き、InspectorからEdit Colliderを選択すると、駒の形に合わせて当たり判定を設定することができます。
問題なければそのままで大丈夫です。 もし、自動での設定ではうまくいかない場合は、手動で設定してください。
駒の動作確認
ここまでで駒(ボール)の作成が完了しました。
再生ボタンを押して、駒(ボール)が重力によって落ちることを確認します。

駒のPrefab化
駒(ボール)をPrefab化して、後で使いやすくします。
Prefabにすると、同じオブジェクトを簡単に複製することができます。 例えば、同じ駒を複数作成する場合などに便利です。
また、Prefabの元データを編集すると、Prefabを使って生成したオブジェクトも一緒に変更されるので、一括で変更することができます。
後で作りますが、スポナーが駒を生成するので、その際はPrefabを使って生成します。
基本的に再利用するオブジェクトや、何度もスクリプトから生成するオブジェクトはPrefab化しておくと便利です。
Prefabsフォルダの作成
Prefabsフォルダをまず作成します。
Projectパネルから Assets フォルダを右クリックし、Create > Folderを選択し、名前を「Prefabs」として作成します。
Prefab化
作成したPrefabsフォルダに駒のゲームオブジェクトをドラッグ&ドロップしてPrefab化します。

Prefab化が完了すると、Prefabsフォルダに駒のPrefabが作成されます。 また、Hierarchy上の駒のゲームオブジェクトも水色になります。Prefabになっていることがわかります。
Prefab化が完了したら、Hierarchy上の駒のゲームオブジェクト不要なので削除しておきます。
他の駒の作成
同じように他の駒も作成します。
基本的には「駒の作成(ボールの作成)で行った手順と同じです。
1点だけ異なる部分としては、駒がマージされて次の駒になると大きな駒に進化する事を考えているので、 Scaleだけ変更します。
例えば、歩兵の次の駒である香車は、Scaleを(1.2, 1.2, 1)に変更します。
同様に、次の駒である桂馬は、Scaleを(1.4, 1.4, 1)に変更します。 のような形で、 駒がマージされるたびに大きくなるように設定します。
今回は 0.2 ずつ大きくなるように設定しましたが、任意の値に変更してください。
すべて完成すると、下記のようになります。

まとめ
今回はUnityでスイカ風のマージパズルゲームの容器と駒(ボール)を作成しました。
次回からは、駒(ボール)を生成するスポナーの作成を行います。
そして、スクリプトを利用してゲームのコアとなる部分を作成していきます。
次回もお楽しみに!