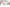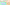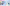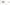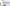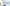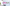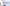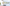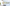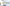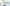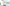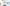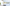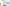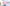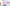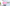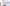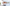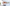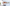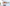配信をしていると、普段の配信や、登録者耐久など配信画面上に現在の登録者数を表示したときありますよね。
今回は、OBSの配信画面上にYouTubeのチャンネル登録者数をリアルタイムで表示する方法を紹介します。
この方法を使えば、配信中にリアルタイムで変化するチャンネル登録者数を視聴者と一緒に確認できるようになります。
さらに、CSSを使って表示をカスタマイズする方法も紹介するので、
自分の配信スタイルに合わせたデザインにすることも可能です。
目次
チャンネル登録者数を表示するメリット
配信画面にチャンネル登録者数を表示することには、以下のようなメリットがあります:
- 視聴者と一緒にマイルストーン(100人、1000人など)を祝うことができる
- チャンネル登録を促進する効果がある
- 配信に動きのある要素が加わり、視覚的な魅力が増す
- 登録者数の変化が見えることでモチベーションアップにつながる
OBSでチャンネル登録者数を表示する方法
Step 1: YouTube Studioからアナリティクスページを開く
- YouTube Studioにログインします
- 左側のメニューから「アナリティクス」をクリックします
- 「現在の登録者数」をクリックします
- このページのURLをコピーしておきます(後でOBSで使用します)
Step 2: OBSにブラウザソースを追加する
- OBS Studioを開きます
- シーンを選択し、「ソース」セクションの「+」ボタンをクリックします
- 「ブラウザ」を選択し、名前を「YouTube登録者数」などわかりやすい名前にします
- 以下の設定を行います:
- URL: Step 1でコピーしたYouTube Studioのアナリティクスページのアドレス
- 幅: 800(必要に応じて調整)
- 高さ: 600(必要に応じて調整)
この時点のプレビューではまだうまく表示されてなくてかまいません
Step 3: ログインして表示を確認する
- ブラウザソースを選択して、「対話(操作)」を選択します
- 画面にはGoogleのログイン画面や、アカウント選択画面などが表示されていると思うので、表示されたブラウザウィンドウでYouTubeアカウントにログインします
- ログイン後、YoutubeStudioのページでStep 1 と同様の手順で、一度OBSの対話ブラウザ内で登録者数情報のページまで表示してください
- ログイン後、OBS画面上で「再読み込み」を押します
- これでチャンネル登録者数のリアルタイムの表示ページががOBS上に表示されるようになります
あとは登録差数の数字の部分をOBS側でトリムして載せるのでもいいのですが、
今回はCSSでデザインを変えてよりおしゃれにしていく方法を 紹介します
CSSでカスタマイズする方法
デフォルトの表示ではYouTube Studioの画面全体が表示されてしまいますが、CSSを使って必要な部分だけを表示し、デザインをカスタマイズすることができます。
ブラウザソースのプロパティを開き、「カスタムCSS」欄に以下のコードを貼り付けることで表示をカスタマイズできます。
今回公開しているCSSの一覧はこんな感じです。
おしゃれなデザインがたくさん!
ハートモチーフ
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: waveSymbol 1.5s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes waveSymbol {
0%, 100% {
transform: translateY(0) scale(1);
}
50% {
transform: translateY(-6px) scale(1.1);
}
}
yta-smooth-counter > #counter {
font-size: 48px;
color: #ffffff;
background: linear-gradient(270deg, #f48fb1, #b39ddb, #81d4fa, #f48fb1);
background-size: 800% 800%;
border: 4px solid #ffffffaa;
border-radius: 20px;
padding: 18px 32px;
display: inline-flex;
align-items: center;
gap: 12px;
box-shadow: 0 0 15px #ffffff88;
animation: waveBg 8s ease infinite;
}
yta-smooth-counter > #counter::before {
content: "💖";
font-size: 46px;
animation: floatHeart 2s ease-in-out infinite;
}
@keyframes waveBg {
0% { background-position: 0% 50%; }
50% { background-position: 100% 50%; }
100% { background-position: 0% 50%; }
}
@keyframes floatHeart {
0%, 100% { transform: translateY(0); }
50% { transform: translateY(-5px); }
}
きらきら星モチーフ、アニメーション
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: waveSymbol 1.5s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes waveSymbol {
0%, 100% {
transform: translateY(0) scale(1);
}
50% {
transform: translateY(-6px) scale(1.1);
}
}
yta-smooth-counter > #counter {
font-size: 52px;
color: #fff8dc;
background: linear-gradient(135deg, #d6bfbc, #b5cccf);
border: 3px solid #ffd700;
border-radius: 24px;
padding: 20px 36px;
display: inline-flex;
align-items: center;
gap: 16px;
box-shadow: 0 0 20px #ffe57f, 0 0 30px #ffd700;
animation: glowStar 2s ease-in-out infinite;
}
yta-smooth-counter > #counter::before {
content: "🌟";
font-size: 48px;
animation: spinStar 6s linear infinite;
}
@keyframes glowStar {
0%, 100% { box-shadow: 0 0 20px #ffe57f, 0 0 30px #ffd700; }
50% { box-shadow: 0 0 30px #ffecb3, 0 0 45px #ffff8d; }
}
@keyframes spinStar {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
さくらモチーフ
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: waveSymbol 1.5s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes waveSymbol {
0%, 100% {
transform: translateY(0) scale(1);
}
50% {
transform: translateY(-6px) scale(1.1);
}
}
yta-smooth-counter > #counter {
font-size: 48px;
color: #ba68c8;
background: rgba(255, 248, 252, 0.95);
border: 2px solid #f8bbd0;
border-radius: 12px;
padding: 10px 20px;
display: inline-flex;
align-items: center;
gap: 8px;
box-shadow: 0 4px 8px rgba(186, 104, 200, 0.2);
}
yta-smooth-counter > #counter::before {
content: "🌸";
font-size: 36px;
}
レトロゲーム風
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: waveSymbol 1.5s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes waveSymbol {
0%, 100% {
transform: translateY(0) scale(1);
}
50% {
transform: translateY(-6px) scale(1.1);
}
}
yta-smooth-counter > #counter {
font-family: 'Press Start 2P', monospace;
font-size: 32px;
color: #00e5ff;
background: #000000dd;
border: 3px dashed #00e5ff;
border-radius: 12px;
padding: 14px 20px;
display: inline-flex;
align-items: center;
gap: 10px;
box-shadow: 0 0 10px #00e5ff, 0 0 20px #00e5ff88;
animation: pulseGlow 1.5s infinite ease-in-out;
}
yta-smooth-counter > #counter::before {
content: "👾";
font-size: 36px;
}
@keyframes pulseGlow {
0%, 100% { box-shadow: 0 0 10px #00e5ff; }
50% { box-shadow: 0 0 20px #00ffff88; }
}
ゆるふわ、動物系(くまちゃん)
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: waveSymbol 1.5s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes waveSymbol {
0%, 100% {
transform: translateY(0) scale(1);
}
50% {
transform: translateY(-6px) scale(1.1);
}
}
yta-smooth-counter > #counter {
font-size: 48px;
color: #6d4c41;
background: rgba(255, 248, 225, 0.9);
border: 3px solid #ffe0b2;
border-radius: 30px;
padding: 18px 28px;
display: inline-flex;
align-items: center;
gap: 12px;
box-shadow: 0 0 10px rgba(255, 204, 128, 0.4);
}
yta-smooth-counter > #counter::before {
content: "🐻";
font-size: 40px;
}
おやすみムーン
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: waveSymbol 1.5s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes waveSymbol {
0%, 100% {
transform: translateY(0) scale(1);
}
50% {
transform: translateY(-6px) scale(1.1);
}
}
yta-smooth-counter > #counter {
font-size: 48px;
color: #9575cd;
background: rgba(235, 222, 255, 0.9);
border: 2px solid #b39ddb;
border-radius: 30px;
padding: 18px 30px;
display: inline-flex;
align-items: center;
gap: 12px;
box-shadow: 0 0 20px #d1c4e9;
animation: moonFloat 3s ease-in-out infinite;
}
yta-smooth-counter > #counter::before {
content: "🌙";
font-size: 44px;
animation: moonGlow 2s ease-in-out infinite;
}
@keyframes moonFloat {
0%, 100% { transform: translateY(0); }
50% { transform: translateY(-6px); }
}
@keyframes moonGlow {
0%, 100% { text-shadow: 0 0 6px #b39ddb; }
50% { text-shadow: 0 0 12px #b39ddb; }
}
アニメ風ポップ、かわいい系
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: animeJump 1.6s cubic-bezier(0.68, -0.55, 0.265, 1.55) infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
@keyframes animeJump {
0%, 100% {
transform: translateY(0) scale(1) rotate(0deg);
}
50% {
transform: translateY(-15px) scale(1.3) rotate(10deg);
}
}
yta-smooth-counter > #counter {
font-size: 54px;
font-weight: 900;
color: #ff1493;
background: linear-gradient(135deg, #ffb3e6, #ffe6f7);
border: 4px solid #ff69b4;
border-radius: 35px;
padding: 25px 40px;
display: inline-flex;
align-items: center;
gap: 16px;
box-shadow:
0 8px 0 #d1477a,
0 12px 20px rgba(255, 20, 147, 0.4);
animation: animeWobble 2s ease-in-out infinite;
position: relative;
}
yta-smooth-counter > #counter::before {
content: "🎀";
font-size: 48px;
animation: ribbonDance 3s ease-in-out infinite;
}
yta-smooth-counter > #counter::after {
content: "💕";
position: absolute;
top: -25px;
right: -15px;
font-size: 30px;
animation: heartFloat 2.5s ease-in-out infinite;
}
@keyframes animeWobble {
0%, 100% {
transform: rotate(0deg) scale(1);
box-shadow: 0 8px 0 #d1477a, 0 12px 20px rgba(255, 20, 147, 0.4);
}
25% {
transform: rotate(1deg) scale(1.02);
box-shadow: 0 10px 0 #d1477a, 0 15px 25px rgba(255, 20, 147, 0.5);
}
50% {
transform: rotate(0deg) scale(1.03);
box-shadow: 0 6px 0 #d1477a, 0 10px 15px rgba(255, 20, 147, 0.3);
}
75% {
transform: rotate(-1deg) scale(1.02);
box-shadow: 0 10px 0 #d1477a, 0 15px 25px rgba(255, 20, 147, 0.5);
}
}
@keyframes ribbonDance {
0%, 100% { transform: rotate(0deg) scale(1); }
33% { transform: rotate(15deg) scale(1.1); }
66% { transform: rotate(-10deg) scale(0.95); }
}
@keyframes heartFloat {
0%, 100% {
transform: translateY(0) scale(1);
opacity: 1;
}
50% {
transform: translateY(-10px) scale(1.2);
opacity: 0.8;
}
}
海中モチーフ、おさかな
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: underwaterSway 2.8s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.23s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.46s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.69s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.92s; }
.counter-symbol:nth-of-type(6) { animation-delay: 1.15s; }
.counter-symbol:nth-of-type(7) { animation-delay: 1.38s; }
.counter-symbol:nth-of-type(8) { animation-delay: 1.61s; }
.counter-symbol:nth-of-type(9) { animation-delay: 1.84s; }
.counter-symbol:nth-of-type(10) { animation-delay: 2.07s; }
.counter-symbol:nth-of-type(11) { animation-delay: 2.30s; }
.counter-symbol:nth-of-type(12) { animation-delay: 2.53s; }
@keyframes underwaterSway {
0%, 100% {
transform: translateX(0) translateY(0) rotate(0deg);
filter: hue-rotate(0deg);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 8px rgba(255, 255, 255, 0.8);
}
25% {
transform: translateX(4px) translateY(-3px) rotate(1deg);
filter: hue-rotate(90deg);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 10px rgba(255, 255, 255, 0.9);
}
50% {
transform: translateX(0) translateY(-6px) rotate(0deg);
filter: hue-rotate(180deg);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 12px rgba(255, 255, 255, 1);
}
75% {
transform: translateX(-4px) translateY(-3px) rotate(-1deg);
filter: hue-rotate(270deg);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 10px rgba(255, 255, 255, 0.9);
}
}
yta-smooth-counter > #counter {
font-size: 52px;
font-weight: bold;
color: #00ced1;
background: radial-gradient(ellipse at center,
rgba(0, 191, 255, 0.2) 0%,
rgba(0, 206, 209, 0.3) 50%,
rgba(0, 100, 139, 0.4) 100%);
border: 3px solid #20b2aa;
border-radius: 50px;
padding: 28px 45px;
display: inline-flex;
align-items: center;
gap: 22px;
box-shadow:
0 0 25px rgba(0, 206, 209, 0.6),
inset 0 0 25px rgba(175, 238, 238, 0.3);
animation: oceanWave 5s ease-in-out infinite;
position: relative;
}
yta-smooth-counter > #counter::before {
content: "🐠";
font-size: 48px;
animation: fishSwim 4s ease-in-out infinite;
}
yta-smooth-counter > #counter::after {
content: "🫧 🫧 🫧";
position: absolute;
bottom: -40px;
left: 50%;
transform: translateX(-50%);
font-size: 24px;
animation: bubbleRise 3s ease-out infinite;
}
@keyframes oceanWave {
0%, 100% {
transform: translateY(0) scale(1);
box-shadow: 0 0 25px rgba(0, 206, 209, 0.6), inset 0 0 25px rgba(175, 238, 238, 0.3);
}
25% {
transform: translateY(-5px) scale(1.02);
box-shadow: 0 0 35px rgba(64, 224, 208, 0.7), inset 0 0 35px rgba(175, 238, 238, 0.4);
}
50% {
transform: translateY(-8px) scale(1.03);
box-shadow: 0 0 30px rgba(0, 255, 255, 0.6), inset 0 0 30px rgba(224, 255, 255, 0.3);
}
75% {
transform: translateY(-5px) scale(1.02);
box-shadow: 0 0 35px rgba(64, 224, 208, 0.7), inset 0 0 35px rgba(175, 238, 238, 0.4);
}
}
@keyframes fishSwim {
0%, 100% { transform: translateX(0) scaleX(1); }
25% { transform: translateX(8px) scaleX(1); }
50% { transform: translateX(0) scaleX(-1); }
75% { transform: translateX(-8px) scaleX(-1); }
}
@keyframes bubbleRise {
0% {
transform: translateX(-50%) translateY(0) scale(0.5);
opacity: 0;
}
20% {
opacity: 1;
}
100% {
transform: translateX(-50%) translateY(-60px) scale(1.2);
opacity: 0;
}
}
ゲーミングフレーム風
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: retroGlow 1.8s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.15s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.45s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.75s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(8) { animation-delay: 1.05s; }
.counter-symbol:nth-of-type(9) { animation-delay: 1.2s; }
.counter-symbol:nth-of-type(10) { animation-delay: 1.35s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.5s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.65s; }
@keyframes retroGlow {
0%, 100% {
transform: skewX(0deg);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 5px #ff00ff,
0 0 10px #ff00ff,
0 0 15px #00ffff;
}
50% {
transform: skewX(-2deg);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 8px #00ffff,
0 0 16px #00ffff,
0 0 24px #ff00ff;
}
}
yta-smooth-counter > #counter {
font-family: 'Orbitron', monospace;
font-size: 54px;
font-weight: bold;
color: #ff00ff;
background: linear-gradient(135deg,
rgba(255, 0, 255, 0.1),
rgba(0, 255, 255, 0.1),
rgba(255, 0, 128, 0.1));
border: 3px solid;
border-image: linear-gradient(45deg, #ff00ff, #00ffff) 1;
border-radius: 0;
padding: 25px 45px;
display: inline-flex;
align-items: center;
gap: 25px;
box-shadow:
0 0 20px #ff00ff,
0 0 40px rgba(255, 0, 255, 0.3),
inset 0 0 20px rgba(0, 255, 255, 0.1);
animation: retroPulse 3s ease-in-out infinite;
position: relative;
transform: perspective(1000px) rotateX(10deg);
}
yta-smooth-counter > #counter::before {
content: "🕹️";
font-size: 48px;
animation: gamepadBounce 2s ease-in-out infinite;
}
yta-smooth-counter > #counter::after {
content: "";
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
background: repeating-linear-gradient(
90deg,
transparent,
transparent 2px,
rgba(255, 0, 255, 0.1) 2px,
rgba(255, 0, 255, 0.1) 4px
);
pointer-events: none;
animation: scanlines 0.1s linear infinite;
}
@keyframes retroPulse {
0%, 100% {
box-shadow:
0 0 20px #ff00ff,
0 0 40px rgba(255, 0, 255, 0.3),
inset 0 0 20px rgba(0, 255, 255, 0.1);
border-image: linear-gradient(45deg, #ff00ff, #00ffff) 1;
}
50% {
box-shadow:
0 0 30px #00ffff,
0 0 60px rgba(0, 255, 255, 0.4),
inset 0 0 30px rgba(255, 0, 255, 0.2);
border-image: linear-gradient(45deg, #00ffff, #ff00ff) 1;
}
}
@keyframes gamepadBounce {
0%, 100% { transform: translateY(0) rotate(0deg); }
50% { transform: translateY(-8px) rotate(10deg); }
}
@keyframes scanlines {
0% { transform: translateY(0); }
100% { transform: translateY(4px); }
}
炎モチーフ、ファイアーテーマ
html, body {
background: transparent !important;
margin: 0;
padding: 0;
overflow: hidden;
}
body * {
visibility: hidden !important;
}
yta-smooth-counter > #counter,
yta-smooth-counter > #counter * {
visibility: visible !important;
}
.counter-symbol {
display: inline-block;
animation: fireFlicker 1.2s ease-in-out infinite;
}
.counter-symbol:nth-of-type(1) { animation-delay: 0s; }
.counter-symbol:nth-of-type(2) { animation-delay: 0.1s; }
.counter-symbol:nth-of-type(3) { animation-delay: 0.2s; }
.counter-symbol:nth-of-type(4) { animation-delay: 0.3s; }
.counter-symbol:nth-of-type(5) { animation-delay: 0.4s; }
.counter-symbol:nth-of-type(6) { animation-delay: 0.5s; }
.counter-symbol:nth-of-type(7) { animation-delay: 0.6s; }
.counter-symbol:nth-of-type(8) { animation-delay: 0.7s; }
.counter-symbol:nth-of-type(9) { animation-delay: 0.8s; }
.counter-symbol:nth-of-type(10) { animation-delay: 0.9s; }
.counter-symbol:nth-of-type(11) { animation-delay: 1.0s; }
.counter-symbol:nth-of-type(12) { animation-delay: 1.1s; }
@keyframes fireFlicker {
0%, 100% {
transform: translateY(0) scaleY(1);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 5px #ff4500,
0 0 10px #ff6347,
0 0 15px #ffa500;
color: #ff4500;
}
25% {
transform: translateY(-4px) scaleY(1.1);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 8px #ff0000,
0 0 16px #ff4500,
0 0 24px #ffa500;
color: #ff0000;
}
50% {
transform: translateY(-2px) scaleY(0.95);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 6px #ff8c00,
0 0 12px #ffa500,
0 0 18px #ffff00;
color: #ff8c00;
}
75% {
transform: translateY(-6px) scaleY(1.05);
text-shadow:
-2px -2px 0 #ffffff,
2px -2px 0 #ffffff,
-2px 2px 0 #ffffff,
2px 2px 0 #ffffff,
0 0 10px #ff6347,
0 0 20px #ff4500,
0 0 30px #ff0000;
color: #ff6347;
}
}
yta-smooth-counter > #counter {
font-size: 56px;
font-weight: bold;
color: #ff4500;
background: radial-gradient(ellipse at center,
rgba(255, 69, 0, 0.3) 0%,
rgba(255, 140, 0, 0.2) 50%,
rgba(139, 0, 0, 0.4) 100%);
border: 3px solid #ff6347;
border-radius: 25px;
padding: 22px 40px;
display: inline-flex;
align-items: center;
gap: 20px;
box-shadow:
0 0 30px rgba(255, 69, 0, 0.7),
0 0 50px rgba(255, 140, 0, 0.4),
inset 0 0 20px rgba(255, 165, 0, 0.2);
animation: flameIntensity 2s ease-in-out infinite;
position: relative;
}
yta-smooth-counter > #counter::before {
content: "🔥";
font-size: 52px;
animation: fireDance 1.8s ease-in-out infinite;
}
yta-smooth-counter > #counter::after {
content: "🔥 💥 🔥";
position: absolute;
top: -45px;
left: 50%;
transform: translateX(-50%);
font-size: 20px;
animation: fireStorm 2.5s ease-in-out infinite;
}
@keyframes flameIntensity {
0%, 100% {
box-shadow:
0 0 30px rgba(255, 69, 0, 0.7),
0 0 50px rgba(255, 140, 0, 0.4),
inset 0 0 20px rgba(255, 165, 0, 0.2);
border-color: #ff6347;
}
50% {
box-shadow:
0 0 40px rgba(255, 0, 0, 0.8),
0 0 70px rgba(255, 69, 0, 0.6),
inset 0 0 30px rgba(255, 215, 0, 0.3);
border-color: #ff0000;
}
}
@keyframes fireDance {
0%, 100% {
transform: rotate(0deg) scale(1);
filter: hue-rotate(0deg);
}
25% {
transform: rotate(5deg) scale(1.1);
filter: hue-rotate(15deg);
}
50% {
transform: rotate(0deg) scale(1.05);
filter: hue-rotate(30deg);
}
75% {
transform: rotate(-5deg) scale(1.1);
filter: hue-rotate(15deg);
}
}
@keyframes fireStorm {
0%, 100% {
transform: translateX(-50%) scale(1);
opacity: 0.8;
}
50% {
transform: translateX(-50%) scale(1.2);
opacity: 1;
}
}
注意事項
こちらのCSSは自己責任でご利用ください
YouTubeのアップデート等によって表示がうまくいかなくなる可能性もあります
数日たったり、アカウントを切り替えたりすると、ログアウト状態になり表示されなくなることがあります、
その場合は一度CSSをクリアして、OBSの対話画面からYoutubeStudioにログインして、
再読み込みをしてください。
まとめ
OBSでYouTubeのチャンネル登録者数を表示する方法を紹介しました。
CSSを使ったカスタマイズ例も紹介しましたが、自分好みにさらに調整することも可能です。
配信画面に個性を出して、視聴者により楽しんでもらえる配信を目指しましょう!